World Pilot: Steering Vision-Language-Action Models with World-Action Priors
Demo
assets/WorldPilot-video-web.mp4 to preview the project video locally.
Overview
Abstract
Vision-Language-Action (VLA) models inherit semantic grounding from large-scale pretraining and perform competently across in-distribution manipulation tasks. This grounding, however, is built on static image-text pairs, whereas manipulation is a continuous, contact-rich process whose dynamics this pretraining cannot capture. We present World Pilot, a VLA framework that augments the policy with priors from a World-Action Model (WAM), routed into the decision chain through two complementary pathways. Latent Steering conditions the perception layer on a scene-evolution latent, and Action Steering supplies an anticipated trajectory as a motion prior to the action generator. Together the two priors equip the VLA with an anticipated view of the scene and a trajectory-level motion hint alongside its semantic conditioning, and the scene-evolution prior remains effective even when supplied by a video-pretrained world model that has not been action-post-trained. World Pilot attains a state-of-the-art Total success rate of 84.7% on the LIBERO-Plus zero-shot OOD benchmark and the highest success rate on every real-robot setting across four manipulation tasks, with the largest margins under shifts in viewpoint, geometry, deformable state, and pose.
Method
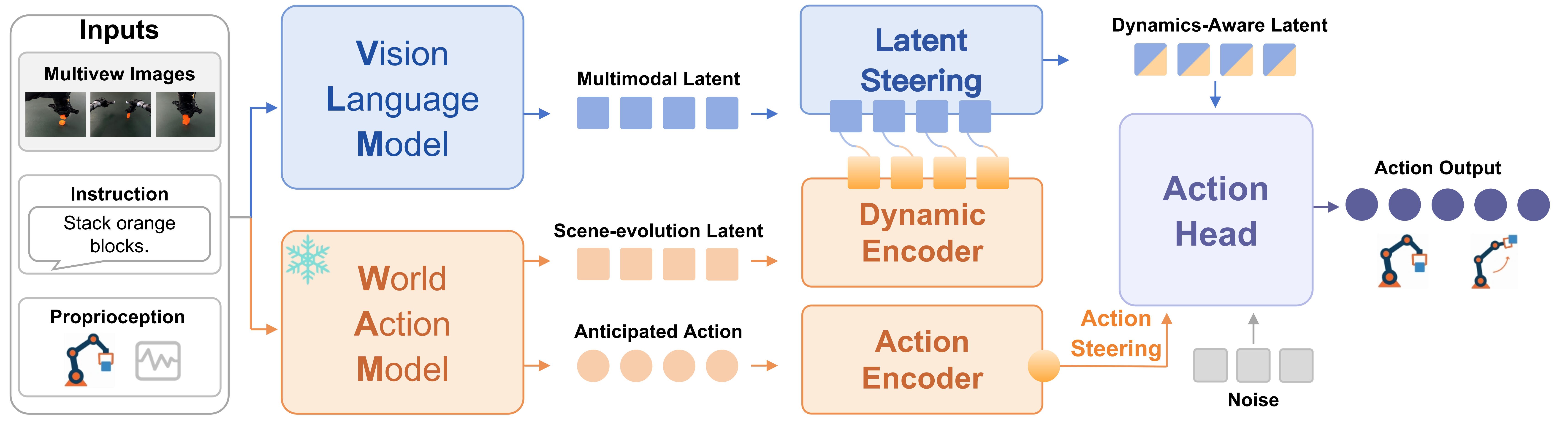
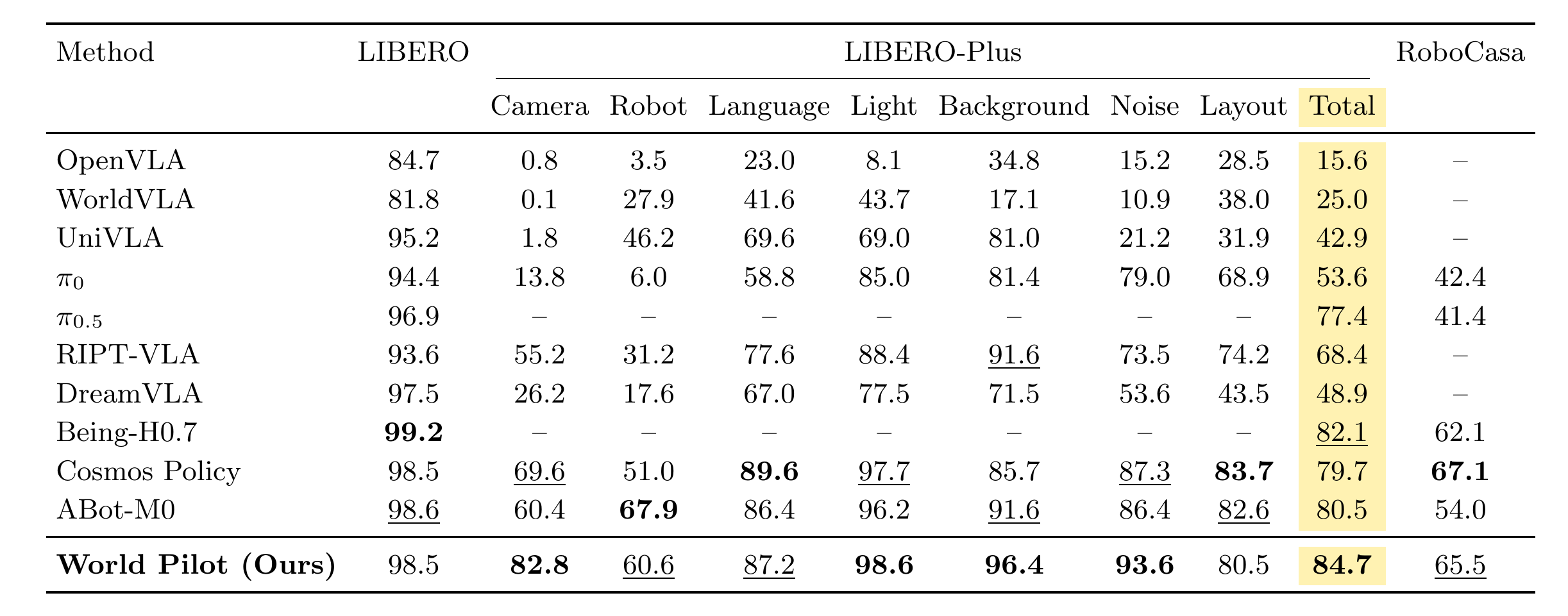
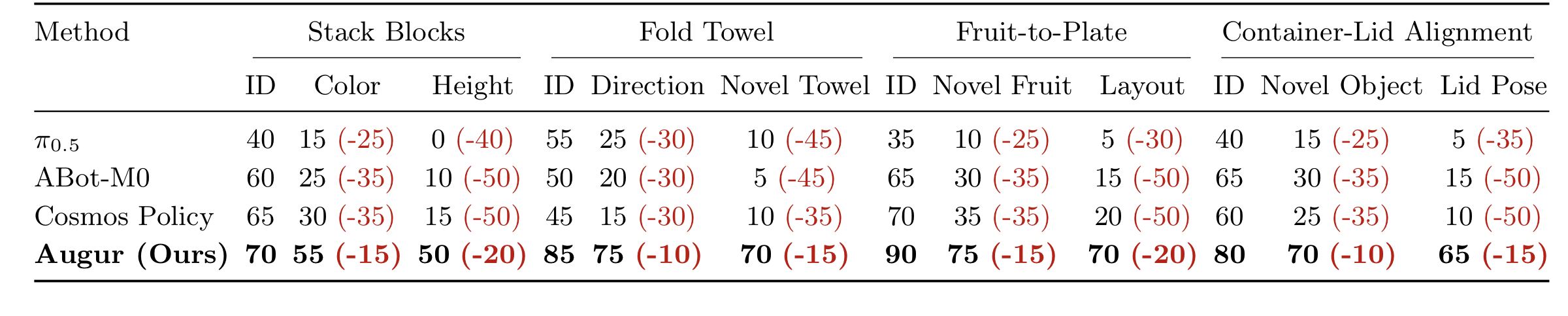
Results
World Pilot improves zero-shot OOD robustness in both simulation and real-robot settings.
Simulation Results
Real-Robot Setup
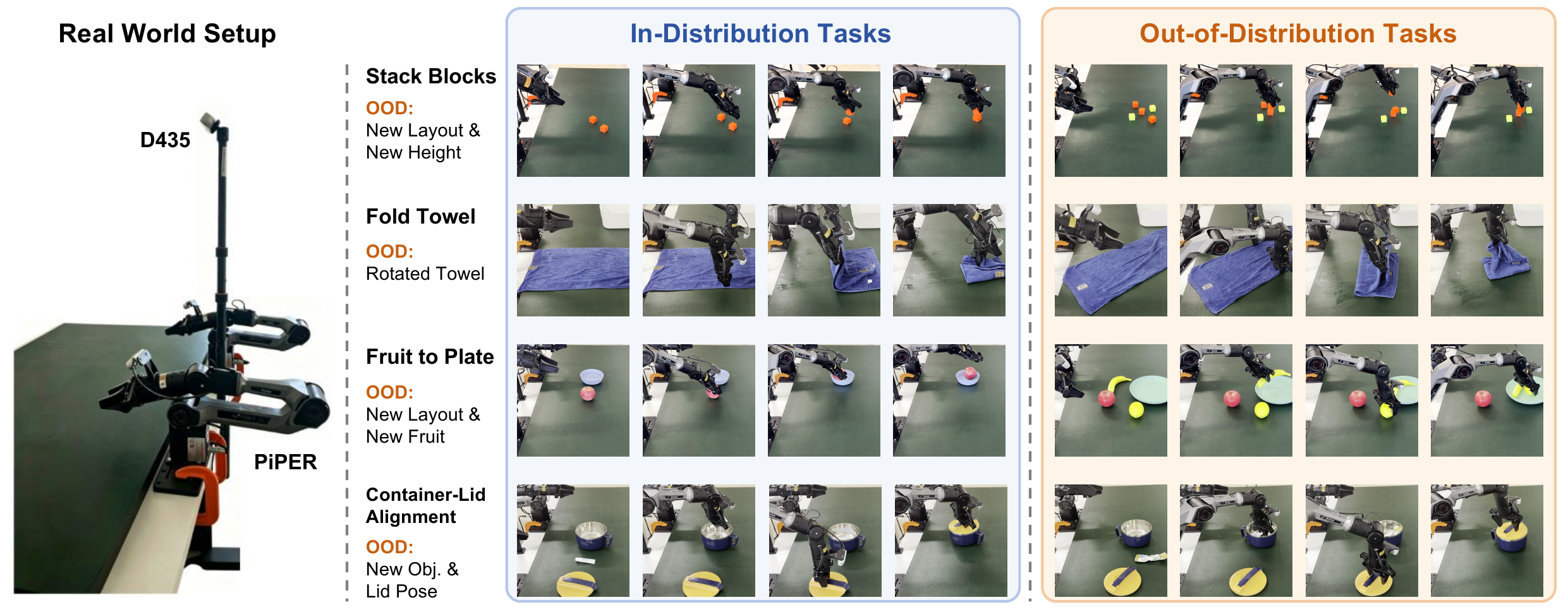
Real-Robot Results
Citation
@article{worldpilot2026,
title={World Pilot: Steering Vision-Language-Action Models with World-Action Priors},
author={Zefu Lin and Rongxu Cui and Junjia Xu and Xiaojuan Jin and Wenling Li and Lue Fan and Zhaoxiang Zhang},
journal={arXiv preprint arXiv:2606.12403},
year={2026}
}